El corpus ha sido desarrollado utilizando PHP como lenguaje principal para la gestión del servidor (Backend). La interfaz de usuario (Frontend) se ha implementado con HTML y JavaScript, incorporando el framework Bootstrap para la estructura, los controles y los elementos visuales de la interfaz. La base de datos se ha diseñado y gestionado mediante MySQL.
El corpus ha sido desarrollado a medida, adaptándose específicamente a las necesidades de la base de datos, y se estructura en dos secciones principales:
- Parte privada, destinada a la gestión interna del corpus. Desde esta sección se administra toda la información asociada a cada muestra, incluyendo la transcripción, el nombre de la red social o la plataforma digital, la fecha, el país y otros metadatos relevantes.
- Parte pública, que corresponde al buscador general, accesible a todos los usuarios. Esta sección permite consultar el contenido del corpus mediante distintos filtros de búsqueda, facilitando la exploración sistemática de los materiales disponibles.
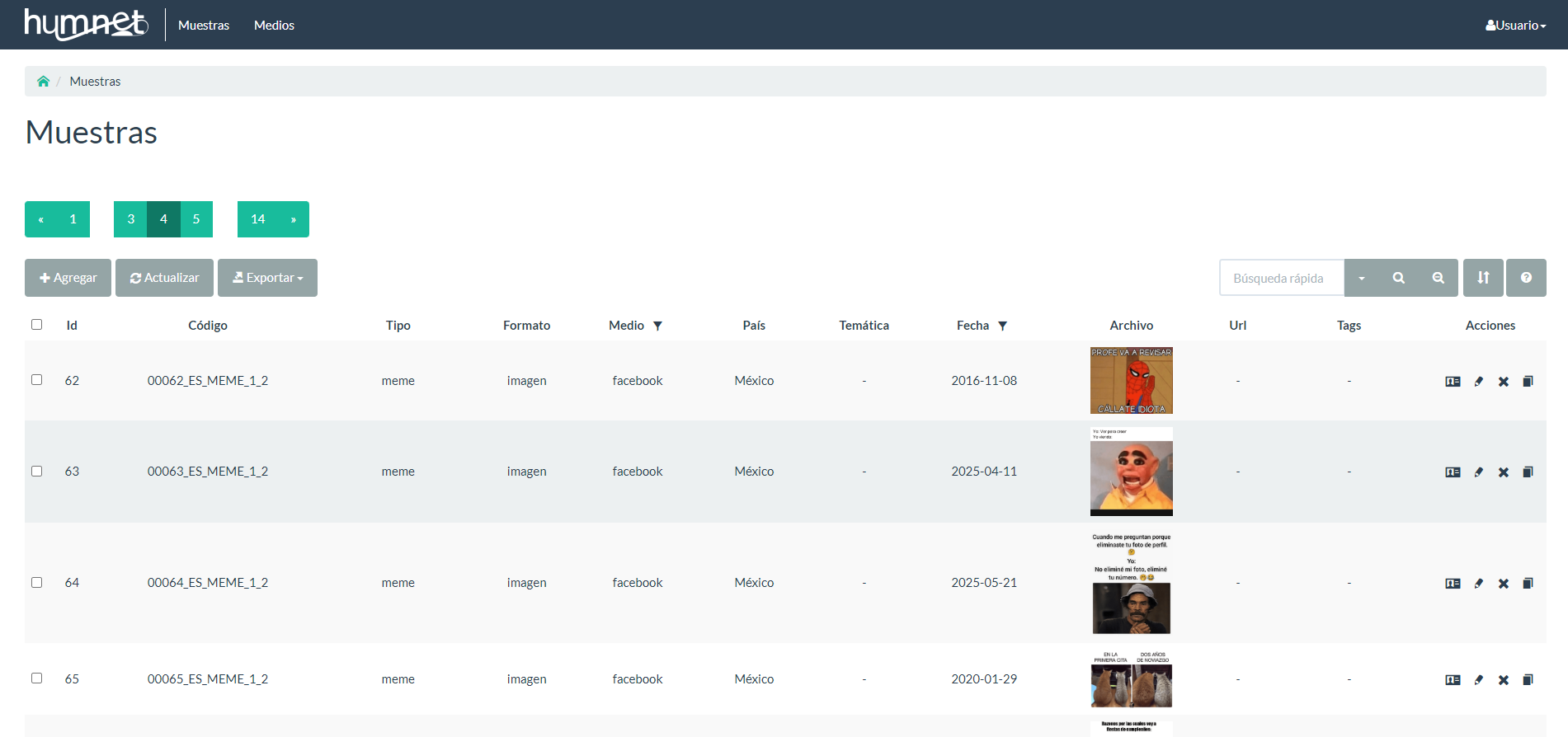
Captura de la zona privada de Humnet
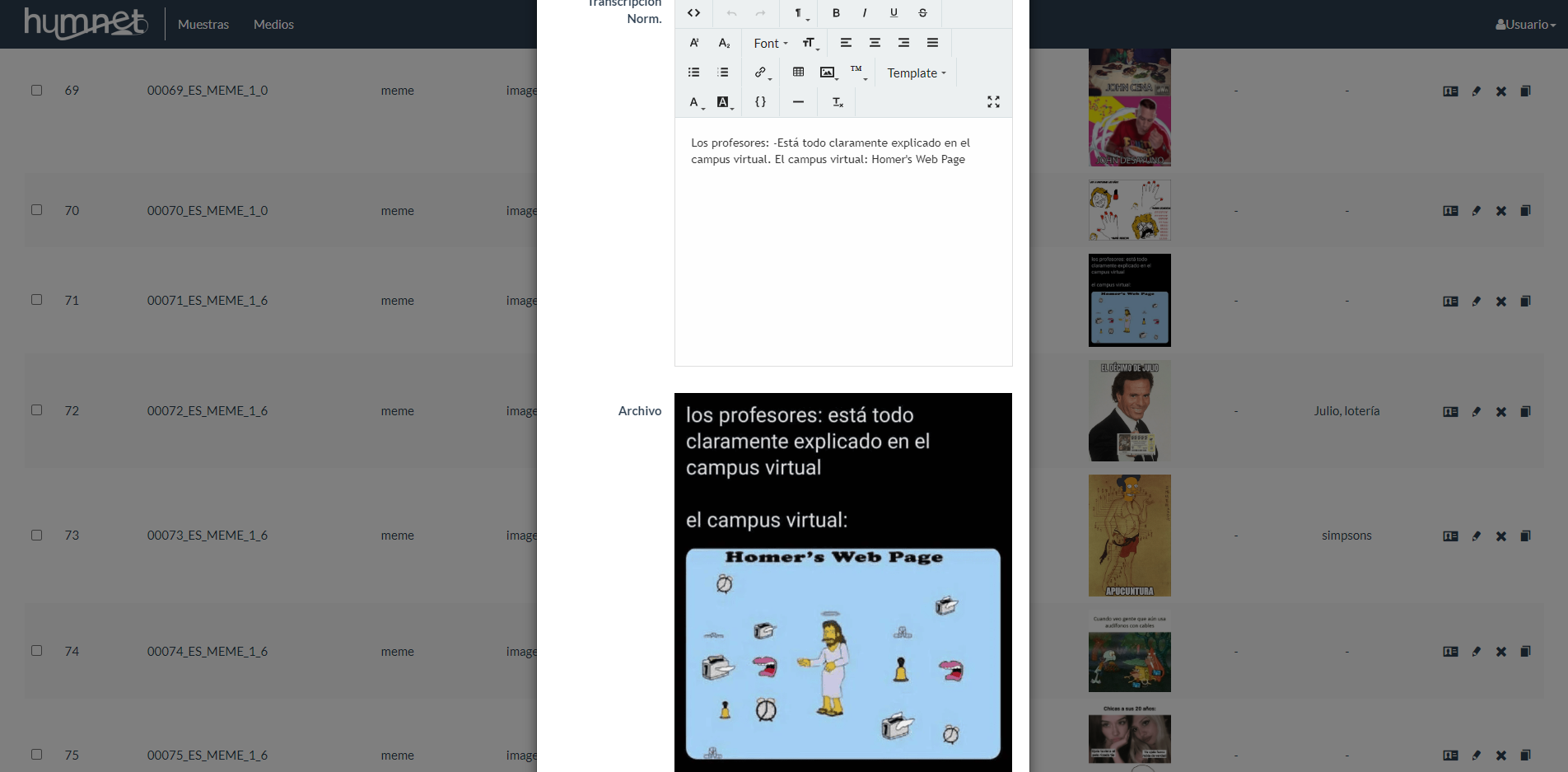
Captura de la edición de muestras de Humnet